Geschrieben von: Christoph Wille
Kategorie: ASP.NET
This printed page brought to you by AlphaSierraPapa
Im Artikel Directory Browsing a la .NET haben wir uns bereits das erste Mal mit dem System.IO Namespace vertraut gemacht, der uns die Klassen für die Dateiverwaltung zur Verfügung stellt. Heute werden wir uns mit den Inhalten der Dateien beschäftigen, und zwar wie man Dateien ausliest. Und das sowohl für Textdateien als auch Binärdateien - was unter ASP mit dem FileSystemObject ja nicht möglich war.
Voraussetzung um den Sourcecode dieses Artikels verwenden zu können ist eine Installation des Microsoft .NET Framework SDK's auf einem Webserver. Weiters setze ich voraus, daß der Leser die Programmiersprache C# zu einem gewissen Grad beherrscht - es finden sich etliche Artikel auf diesem Server, um das notwendige Wissen zu erlernen
Die häufigste Aufgabe ist sicher das Auslesen von Textdateien. Und "innerhalb" dieses Aufgabenbereichs gibt es auch noch eine andere Häufigkeit: das Auslesen von gesamten Zeilen. Der folgende Sourcecode (textreader2.aspx) zeigt genau dies, und gibt sich selbst am Browser wieder aus (eine absichtliche "Sicherheitslücke").
<% @Page Language="C#" %>
<% @Import Namespace="System.IO" %>
<%
StreamReader stmReader = File.OpenText(Server.MapPath("textreader2.aspx"));
string strLine;
while (null != (strLine = stmReader.ReadLine()))
{
strLine = Server.HtmlEncode(strLine);
Response.Write(strLine +"<br>\r\n");
}
stmReader.Close();
%>
Das Ergebnis sieht wie folgt aus:
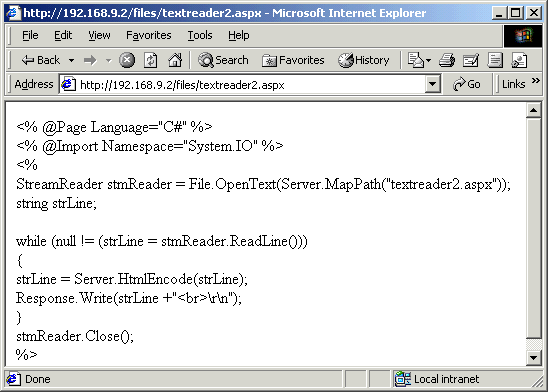
Nun aber zurück zum Sourcecode, um ihn einer genaueren Untersuchung zu unterziehen. Daß wir den System.IO Namespace importieren müssen, ist hoffentlich mittlerweile bei jedem in Fleisch und Blut übergegangen. Interessanter ist dann auch schon, wie ich an die Datei komme:
StreamReader stmReader = File.OpenText(Server.MapPath("textreader2.aspx"));
Ich bediene mich hier des StreamReader Objekts, welches ein bequemes textuelles Auslesen einer Datei erlaubt - ich könnte sogar automatische Zeichensatzkonvertierungen anfordern! An diesen StreamReader komme ich über die statische OpenText Methode des File Objekts, welche als Parameter nur den absoluten (physikalischen) Pfad der Datei erwartet.
Das Auslesen der Zeilen der Datei bewerkstelligt man mit Hilfe der ReadLine Methode und einer simplen while Schleife. Die Endbedingung (Dateiende erreicht) ist die, daß die ReadLine Methode null zurückliefert:
while (null != (strLine = stmReader.ReadLine()))
{
strLine = Server.HtmlEncode(strLine);
Response.Write(strLine +"<br>\r\n");
}
Als guter Bürger schließt man zu guter Letzt noch den verwendeten StreamReader, und das war es dann auch schon.
stmReader.Close();
Ich habe es in der Einleitung ja bereits erwähnt - Binärdateien waren mit dem FileSystemObject eines der "Geht nicht!" Themen. Bei ASP.NET und .NET ist dem nicht länger so, man hat sogar soviel Auswahl, daß ich heute nur auf eine der vielen Möglichkeiten eingehen möchte.
Im Beispiel binarydump.aspx lese ich die Bilddatei test.png ein (diese stammt original aus dem Artikel On-the-fly Generierung von Graphiken), und gebe Sie binär an den Client mittels Response.BinaryWrite zurück:
<% @Page Language="C#" %>
<% @Import Namespace="System.IO" %>
<%
string strFile = Server.MapPath("test.png");
Stream stmRead = File.OpenRead(strFile);
int nBufferSize = 255, nReadBytes = 0, nTotalBytes = 0;
byte[] arrByte = new byte[nBufferSize];
Response.ClearContent();
Response.ContentType = "image/png";
while (0 != (nReadBytes = stmRead.Read(arrByte, 0 , nBufferSize-1)))
{
nTotalBytes += nReadBytes;
if (nReadBytes == nBufferSize)
Response.BinaryWrite(arrByte);
else
{
byte[] arrCopy = new byte[nReadBytes];
Array.Copy(arrByte, 0, arrCopy, 0, nReadBytes);
Response.BinaryWrite(arrCopy);
}
}
Response.End();
%>
Daß es funktioniert hat, beweist der folgende Screenshot:
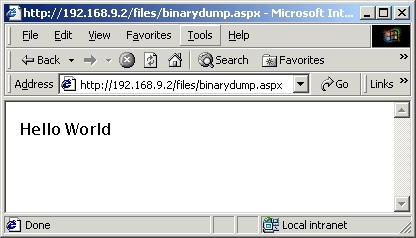
Im Sourcecode möchte ich speziell auf den if Block im while Statement eingehen:
if (nReadBytes == nBufferSize)
Response.BinaryWrite(arrByte);
else
{
byte[] arrCopy = new byte[nReadBytes];
Array.Copy(arrByte, 0, arrCopy, 0, nReadBytes);
Response.BinaryWrite(arrCopy);
}
Der Grund für diesem Heck-Meck ist der, daß die BinaryWrite Methode nur ein ganzes Array schicken kann, allerdings keine Teile (in der Art: Startindex + Anzahl der zu schickenden Bytes aus dem Array). Aus diesem Grund muß ich für den letzten Datenblock, der ja (fast) immer kleiner als mein Buffer ist, eine Umkopierroutine auf ein Array der richtigen Größe einbauen. Es ist zwar nicht "schön", erfüllt aber den Zweck mehr als ausreichend.
Obwohl ich heute nur jeweils eine von vielen Möglichkeiten des Dateiauslesens besprochen habe, zeigen bereits diese Beispiele, daß ASP.NET gerade im Hinblick auf das Arbeiten mit Dateien die bessere, neue Zukunft ist.
This printed page brought to you by AlphaSierraPapa
Klicken Sie hier, um den Download zu starten.
http://www.aspheute.com/code/20000929.zip
Applikationen aus ASP.NET ausführen
http:/www.aspheute.com/artikel/20010220.htm
Dateien auslesen mit VB.NET
http:/www.aspheute.com/artikel/20010221.htm
Dateien umbenennen
http:/www.aspheute.com/artikel/20020409.htm
Directory Browsing a la .NET
http:/www.aspheute.com/artikel/20000804.htm
Online File Management System mit ASP.NET und C# - Teil 2
http:/www.aspheute.com/artikel/20021105.htm
On-the-fly Generierung von Graphiken
http:/www.aspheute.com/artikel/20000728.htm
Thumbnailgenerierung in .NET
http:/www.aspheute.com/artikel/20020225.htm
©2000-2006 AspHeute.com
Alle Rechte vorbehalten. Der Inhalt dieser Seiten ist urheberrechtlich geschützt.
Eine Übernahme von Texten (auch nur auszugsweise) oder Graphiken bedarf unserer schriftlichen Zustimmung.