
Bild 1: Webseite nicht gefunden, diesmal auf japanisch.
Geschrieben von: Christian Koller
Kategorie: ASP Tricks
This printed page brought to you by AlphaSierraPapa
Aus dem Tagebuch eines Programmierers
Was treibt sie an, was treiben sie?
Nur die wenigsten Programmierer werden in die Verlegenheit kommen eine japanische oder gar chinesische Website zu programmieren. Trotzdem erhielt ich vor kurzem eine Email, in der ich um Rat gefragt wurde. Involviert war eine chinesische Website, genauer gesagt, ein Webformular, das in ASP auszuwerten war.
Aufgrund meiner Erfahrung mit Unicode in Zusammenhang mit ASP oder Datenbanken dachte ich bei mir, es wäre sicherlich eine einfache Sache: nur ein paar chinesische Schriftzeichen in einem Formular, das zu einer ASP Datei geschickt werden sollte.
Doch ich hatte nicht mit den gemeinen Fallen gerechnet, die mir auf meinem Weg auflauern würden.
Aber zurück zum Anfang: wie ich der geheimnisvollen Email eines verzweifelten Programmierers entnehmen konnte, war das mit den chinesischen Schriftzeichen und ASP so eine Sache. Natürlich wollte ich mich davon mit eigenen Augen überzeugen und wagte mich in die Höhle des Löwen. Genauer gesagt, zuerst in die Höhle des Drachen.
Ein Souvenier meiner ausgedehnten Streifzüge durchs Internet war eine japanische Fehlermeldung, die mir mit blümigen Worten von einem HTTP 404 Fehler gekündet hatte. Eingeweihte wissen: HTTP Fehler 404, das ist wie wenn man an der Türe eines größen Hauses läutet und keiner macht auf. Oder wie einer meiner amerikanischen Kollegen so treffend zu sagen pflegt: File Not Found.
Bild 1: Webseite nicht gefunden, diesmal auf japanisch.
Ich machte mich also auf den Weg, bei mir meine treuen Begleiter Homesite 4.0, IIS 5.0 und Internet Explorer 5.5. Sie alle hatten mir bisher hervorragende Dienste erwiesen, ich wußte, wenn ich das Rätsel lösen wollte, dann nur mit diesen Werkzeugen.
So ging ich daran ein Formular zu basteln, das in einer Unicode codierten HTML Seite eingebettet war. Kühl rechnete ich damit, daß der Auswertungsteil in ASP, da ebenso auf Unicode basierend, eigentlich kompatibel sein müßte.
Um das Formular mit fremdartigen, ja unverständlichen Schriftzeichen zu testen, nahm ich eben jene 404 Meldung auf japanisch her, die schon seit geraumer Zeit auf meiner Festplatte friedlich vor sich hin geschlummert hatte.
Mit einem gewissen Kribbeln in der Magengegend spielte ich also das folgende ASP File auf den IIS 5.0 Server. Eingeweihte wissen bereits: das folgende Skript (20001010_unicode.asp) verweigert auf einem IIS 4.0 seinen Dienst - Windows NT 4.0 kann die Codepage 65001 (Unicode) nicht liefern, also höchste Zeit um in Pension zu gehen und Platz für Windows 2000 Server zu machen!
<% @Codepage = 65001 %>
<%
' Achtung: Codepage Unicode (65001) kann nur unter IIS 5.0 angegeben werden
' Wenn Sie es mit einem hinterhaeltigen IIS 4.0 zu tun haben, so verweigern
' Sie einfach die Angabe jeglicher Codepage! Er wird Sie mit sonderbaren
' Zeichen strafen, aber so ist die Welt.
%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>Unicode mit Japanisch (Banzai!)</title>
<meta name="Author" content="christian.koller@aspexpert.com">
<!-- Achtung: Unicode (charset=UTF-8) versteht nicht jeder
Browser, daher mit Vorsicht zu geniessen -->
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=UTF-8">
</head>
<body>
Unerschrocken erdacht und getestet von
<a href="mailto:christian.koller@aspexpert.com">Christian Koller</a>!
<br><br>
<%
' Ist das Formular abgeschickt? Die gute alte Servervariable
' Content_Length gibt bereitwillig Auskunft
If Request.ServerVariables("CONTENT_LENGTH") <> 0 Then
isPostBack = True
' Lese den abgesendeten Text aus
content = Request.Form("content")
' Schreibe den Text zum Browser
' (Ein Roundtrip der schwindligen Art):
' Ersetze davor alle Returns mit "<BR>", der Browser wird
' es dir danken (Moegen die Goetter mit dir sein!)
strOut = Replace(content, chr(13), "<BR>")
strOut = Replace(strOut, chr(10), "")
Response.write "Empfangen:<br>" & strOut & "<br><br>" & vbcrlf
' Achtung: Server.HTMLEncode reagiert sehr gereizt
' wenn unter Unicode aufgerufen: Fuer Fehler keine Haftung
contentHTMLEncode = Server.HTMLEncode(content)
' Schreibe die Unicode Codes aller Buchstaben zum Browser,
' Stueck fuer Stueck sich naehernd der Wahrheit
' (die bekanntlich irgendwo da draussen liegt ...)
For intI = 1 to Len(content)
strChar = Mid(content,intI, 1)
AscwChar = ASCW(strChar)
' Achtung Falle: Wegen eines Fehlers in der AscW Implementation:
' Ein Wert kleiner als Null darf nicht ungestraft hingenommen werden!
If AscwChar < 0 Then AscwChar = AscwChar + 65536
' Schreibe den Unicode Code und den Buchstaben zum Browser,
' moege er das Antlitz des Programmierers strahlen lassen
Response.Write AscwChar & " = " & strChar & _
"<br>" & vbcrlf
Next
Response.Write "<br><br>"
' Eigenhaendig einen HTML-enkodierten String "zusammenbauen" -
' (Heimwerken leicht gemacht)
strHTMLEncoded = ""
For intI = 1 to Len(content)
strChar = Mid(content,intI, 1)
AscwChar = ASCW(strChar)
' Schon wieder die Falle in ASCW:
If AscwChar < 0 Then AscwChar = AscwChar + 65536
' Zeichen einfach als &#xxxxx; ausgeben.
' Sei xxxxx der Unicode Wert des Zeichens -
' und das Glueck ist auf Deiner Seite:
strHTMLEncoded = strHTMLEncoded & "&#" & AscwChar & ";"
Next
' Schreibe den HTML-enkodierten String zum Browser
' Keine Angst, der Browser beisst nicht,
' zumindest nicht bei Unicde!
Response.Write "HTML-enkodierter String:<br>"
strOut = Replace(strHTMLEncoded, " ", "<BR>")
strOut = Replace(strOut, " ", "")
Response.Write strOut & vbcrlf
Else
isPostBack = False
End If
%>
<form action="<%= Request.ServerVariables("SCRIPT_NAME") %>" method="POST">
<!-- Der folgende Inhalt is unicode-kodiertes Japanisch -->
<textarea name="content" cols="40" rows="10">
HTTP エラー 404
404 見つかりません
</textarea>
<input type="Submit" name="Submit" value="Submit">
</form>
<br>
<a href="<%= Request.ServerVariables("SCRIPT_NAME") %>">Zurueck</a>
</body>
</html>
Vorsichtig startete ich den Internet Explorer - die Eingabe der Adresse meines Entwicklungsservers war Routine. Wohlwollend konnte ich das erwartete, erste Ergebnis betrachten:
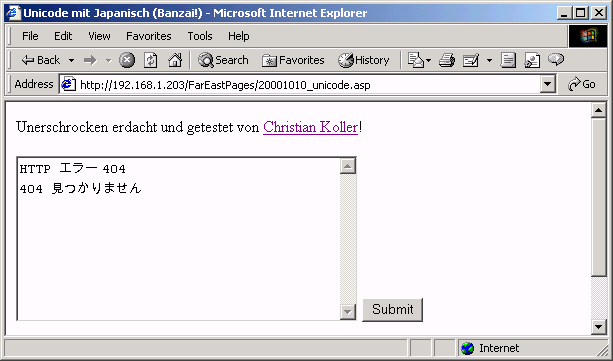
Bild 2: Browser bei Anzeige der ASP Datei mit japanischen Schriftzeichen.
Was würde nun passieren, wenn ich den Submit Button drückte? Würde der Browser wohl die richtigen Zeichen in verständlicher Kodierung an den Webserver schicken; wäre ASP in der Lage, die Zeichen zu lesen und zu deuten? Fragen über Fragen. Doch mit der Entschlossenheit eines Samurai sandte ich das Formular zum Server, mein Schicksal in die Hände der Götter, mein Geist bis zum Zerreißen gespannt. Blitzschnell ging ich in Gedanken jeden einzelnen Schritt durch, der nun unabwendbar seinen Weg gehen würde:
Der Browser sendet die Zeichen, als Unicode Zeichen kodiert, über das ihm wohlvertraute HTTP Protokoll zum Webserver. Er schickt die Zeichen als Unicode, da dies das augenblickliche Characterset sozusagen das Karma der Seite, bestimmt!
Am IIS 5.0 würde der Aufruf bei der ASP Seite Gehör finden, der Webserver die Daten huldvoll in Empfang nehmen und mit gebührendem Respekt zum Request Objekt weiterreichen.
So liegt des Textes Schicksal nun in des Skriptes Händen. Gespeichert in der Variable content verweilt der Text doch nur einen kurzen Augenblick. Ja, in der Tat es war ein KLEINER Inhalt, doch um so abenteuerlicher sein Weg:
Denn schon schreibt das ASP Skript den gespeicherten Text wieder zum Browser, eine Art Boomerang. Doch damit der Text lesbar im Browser wieder erscheint, muß der Server die Codepage 65001 (Uniocode) in Verwendung nehmen, sozusagen als Umschlag, damit die Buchstaben richtig, unbeschadet und unverfälscht am Browser ankommen:
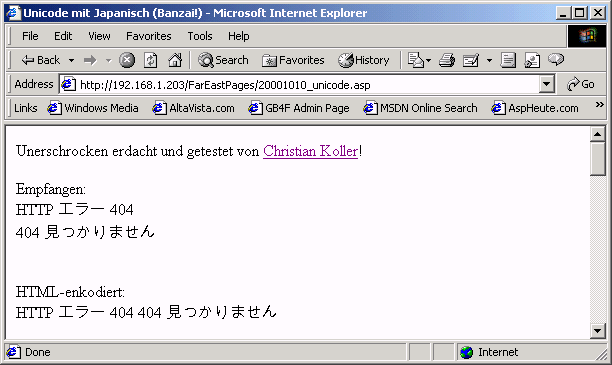
Bild 3: Die Ankunft, unbeschadet und unversehrt!
Für die direkte Ausgabe mittels Response.Write(content) ist es nicht von Bedeutung, ob die Codepage in der ASP Seite explizit auf Unicode (65001) gesetzt ist. Die Zeichen der Botschaft finden auch so wieder unbeschadet ihren Weg zum Browser. Jedoch würde eine nicht gesetzte Codepage für den Befehl Server.HTMLEncode bedeuten, daß die Zeichen vollkommen falsch kodiert zum Browser geschickt werden:
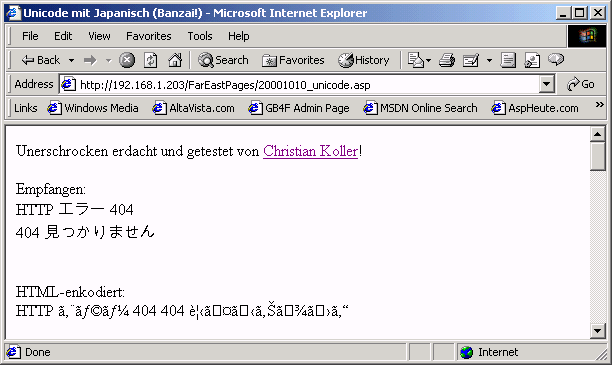
Bild 4: Kamikaze?
Das Aufzeigen der Unicode Codes der einzelnen Schriftzeichen, vom Listing mit Hilfe einer For Schleife und den String Funktionen Mid und ASCW vollbracht. ASCW liefert dabei nur den ASCII Wert eines Unicode Schriftzeichens zurück:
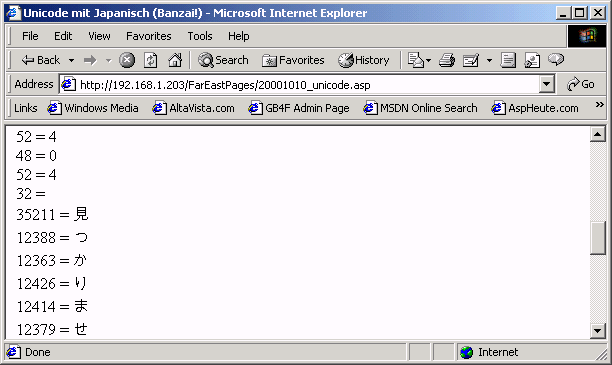
Bild 5: Die Buchstaben und ihre Unicode Werte
Eine kleine Episode am Rande: das in Bild 5 mit dem Wert 35211 gekennzeichnete Schriftzeichen hat mir den Fallstrick gezeigt, den die ASCW Funktion birgt - für manche Zeichen liefert sie negative Werte, ganz entgegen jeder Konvention und Vernunft! Für jenes bewußte Zeichen mit dem Unicode Wert 35211 liefert ASCW den Wert -30325, man stelle sich vor! Diesen Lapsus muß der Programmierer in seiner Weisheit korrigieren, wobei ein Addieren der magischen Zahl 65536 (2 hoch 16) zu negativen ASCW Werten wahrlich Wunder wirkt!
AscwChar = ASCW(strChar)
' Schon wieder die Falle in ASCW:
If AscwChar < 0 Then AscwChar = AscwChar + 65536
Zu guter letzt bastelt unsere tapfere ASP Datei noch eine Zeichnekette zusammen, die aus den einzelnen Schriftzeichen des japanischen Textes bestehen - jeweils in der Form &#xxxxx; kodiert. Der Wert xxxxx steht dabei für den Unicode Wert des jeweiligen Zeichens. Und ebenso erwartungsgemäß sieht die Ausgabe im Internet Explorer aus:
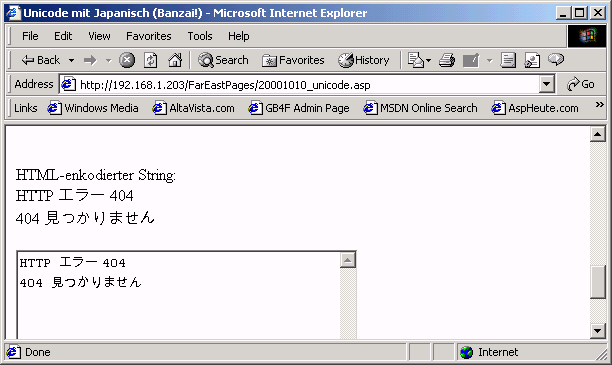
Bild 6: HTMLEncode einmal anders!?!
Auch hier ist es von immenser Wichtigkeit, daß die Codepage der Seite auf Unicode gesetzt ist. Nicht sehen könnt Ihr sonst die Schönheit oder die Bedeutung der Schrift!
Für diejenigen, die dieses Skript unter Netscape ausführen eine eindringliche Warnung! Nicht einweihen wird Euch dieser Browser in die Geheimnisse der Unicode-Verschlüsselung - nicht fähig ist er doch dazu, erkennt er doch nicht die verborgenen Botschaften, die jedem Unicode Zeichen inne wohnen!
Das erste Skript ein voller Erfolg - ich lehnte mich in meinen Lehnstuhl und genehmigte mir erstmal eine dicke Zigarre. Alles schien so einfach, so klar. Wo sollten hier, in diesem fast vollkommenen Räderwerk, die Probleme lauern, die mein geheimnisvoller Informant mir mitgeteilt hat?
Ich analysierte noch einmal die Email, nahm Fingerabdrücke, verfolgte die Route der Email zurück, doch all dies half nichts. Also entschloß ich mich, mein unerschöpfliches Nachschlagewerk, die Bibliothek der hohen Programmiererkunst zu befragen - die Microsoft Developer Network Library, oft auch nur kurz MSDN genannt.
Schon oftmals in fast hoffnungslosen Situationen fand ich den rettenden Ausweg in den weisen Schriften. Auch diesmal sollte mir das Glück treu sein!
War nicht in der Email von "Chinesisch" die Rede? Also durchforstete ich die Weiten der MSDN nach chinesischen Codepages, sowohl für den Browser als auch für den Server - und meine Mühen wurden belohnt.
Ich stieß auf ein längst vergessenes Dokument mit dem eindeutigen Titel Appendix G DBCS/Unicode Mapping Tables. Es fiel mir wie Schuppen von den Augen und ich kombinierte blitzschnell: Chinesische Schriftzeichen - chinesisches Characterset im Browser! Wie sonst sollten chinesische Schriftzeichen dargestellt werden, wenn man nicht dem Browser die Anwesenheit derselbigen mitteilte? Einzig und allein die folgende HTML Zeile änderte die ganze Situation grundlegend:
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=big5">
Diese kleine Anweisung war verantwortlich dafür, daß die chinesischen Schriftzeichen korrekt im Browser dargestellt werden! Um ein wenig ins Detail zu gehen, der Characterset Big5 ist das Synonym für die Codepage für "Traditionelles Chinesisch". Die zugehörige server-seitige Codepage hat den Wert 950, soviel stand fest.
Nun gut, gar nicht faul änderte ich einfach das Skript, das mit der japanischen Schrift so hervorragend harmoniert hatte, und benutzte anstatt der Unicode Zeichensätze im Browser die Big5 Zeichensätze:
<% @Codepage = 950 %> <% ' Codepage Unicode (950) steht fuer traditionelles Chineisch (big5), ' und in unserem Fall auch fuer Probleme! %> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <html> <head> <title>Japanisch als traditionelles Chinesisch verkleidet</title> <meta name="Author" content="christian.koller@aspexpert.com"> <!-- Achtung: Big5 Characterset: Traditionelles Chinesisch --> <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=big5"> </head> <body> ...
Das Script glich dem alten Skript bis aufs Haar, nur die Kodierung wechselte von Unicode auf "Traditionelles Chinesisch" (Big5). Ernüchterung stellte sich bei mir ein, als ich das Formular abgeschickt hatte:
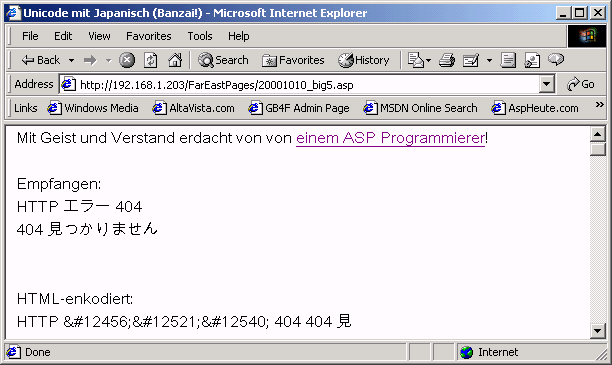
Bild 7: Traditionelle Chinesische Ernüchterung
Der direkt gesendete Text kam im Browser noch unversehrt an. Doch schon bei der Ausgabe des Befehls Server.HTMLEncode, und erst recht bei der Auflistung der einzelnen Zeichen überkam mich eine tiefe Müdigkeit - leichte Ratlosigkeit, gepaart mit ungläubigem Kopfschütteln bestimmte meine Reaktion.
Der Schrecken saß tief. Was war genau passiert, dies galt es zu klären, eindeutig aufzuzeigen, wo und warum die Schriftzeichen nicht mehr die selben waren, die Ihren Weg zum Server angetreten hatten:
Im Eingabfeld des Formulars wurden die Zeichen noch so angezeigt, wie sie wohl jeder Japaner ohne Mühe lesen könnte.
Minutiös konstruierte ich den Weg, den die Informationen zum Server und wieder zurück zum Browser genommen hatten, und nach einiger Suche fand ich schließlich die wahre Ursache für das Dilemma heraus. Wie aus der Ausgabe der einzelnen Schriftzeichen bzw. Buchstaben unschwer zu erkennen ist, werden die meisten Zeichen in der Form &#xxxxx; bereits in der Variablen content gespeichert.
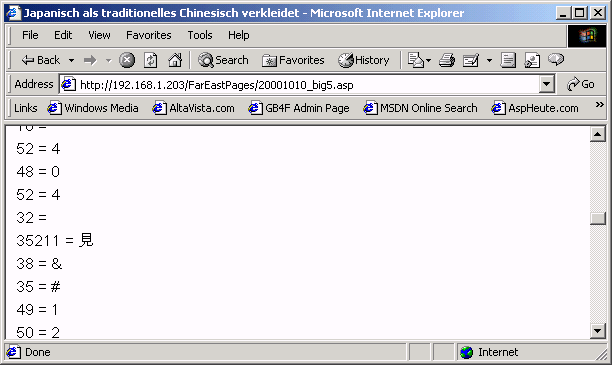
Bild 8: Inhalt der Variablen content
Damit dies der Fall sein kann, muß bereits das Request Objekt die Zeichen in dieser Form gespeichert haben. Nur so ist es zu erklären, daß bei der nachfolgenden Zuweisung die Variable content den unerwarteten aber einwandfrei festgestellten Inhalt birgt.
content = Request.Form("content")
Doch wie sollte das Request Objekt zu diesem Inhalt kommen? Nach Abwägung aller Fakten bleibt als einzig logische Schlußfolgerung, daß bereits der Browser die Zeichen nicht vernünftig kodiert zum Server geschickt hat, sondern direkt als &#xxxxx;! Damit ist ein einzelnes Zeichen nicht mehr mittels DBCS (Double Byte Character Set) kodiert, sondern liegt als HTML/Unicode-Darstellungswert vor.
Wie Sie sich, geschätzter Leser, sicherlich vorstellen können, ist die Handhabung eines solchen Inhaltes alles andere als leicht. Noch dazu sind manche Zeichen als als DBCS kodiert, andere als &#xxxxx;. Das Chaos ist perfekt!
Was kann man tun, um der Misere zu entrinnen?
Ich konsultierte noch einmal die MSDN und fand einen anderen Zeichensatz, mit dem sich chinesische Schriftzeichen darstellen lassen. Den Zeichensatz "Simplified Chinese", Codepage 936.
Rasch schrieb ich das Beispiel um, verwendete im HTML als auch in der ASP Seite den "Simple Chinese" Zeichensatz, und wie durch ein Wunder, einem Sonnstrahl in finsterem Walde gleich --- es funktionierte! Ich konnte beliebige chinesische Zeichen zum Server senden, wo Sie wohlbehalten und unversehrt in der Variable content gespeichert wurden.
Erleichtert legte ich den gelösten Fall zu den Akten.
Big5 liefert GROSSE Probleme, wenn man in dieser Codierung ein Formular zum Server schickt.
Der Ausweg liegt darin, sich mit dem simplified Chinese Characterset zufrieden zu stellen, das vielleicht ein paar tausend Zeichen weniger enthält, dafür aber alle vernünftig kodiert zum Webserver schickt!
This printed page brought to you by AlphaSierraPapa
Klicken Sie hier, um den Download zu starten.
http://www.aspheute.com/code/20001010.zip
Überprüfen von HTML-Formularen mit ASP
http:/www.aspheute.com/artikel/20000522.htm
@-Direktiven auf ASP Seiten
http:/www.aspheute.com/artikel/20000405.htm
Unicode und ASP (Einführung)
http:/www.aspheute.com/artikel/20000831.htm
Zahl, Datum und Währung korrekt formatiert ausgeben
http:/www.aspheute.com/artikel/20020704.htm
Appendix G DBCS/Unicode Mapping Tables
http://msdn.microsoft.com/library/default.asp?URL=/library/books/devintl/S24CD.HTM
Character- und Codesets
http://msdn.microsoft.com/workshop/database/tdc/reference/CharSet.asp
Developing International Software
http://msdn.microsoft.com/library/default.asp?URL=/library/books/devintl/S24AE.HTM
Microsoft Developer Network Library
http://msdn.microsoft.com/default.asp
©2000-2006 AspHeute.com
Alle Rechte vorbehalten. Der Inhalt dieser Seiten ist urheberrechtlich geschützt.
Eine Übernahme von Texten (auch nur auszugsweise) oder Graphiken bedarf unserer schriftlichen Zustimmung.